Last modified: 2026-03-03 00:59:16 +0900
View History
인덱스 설계가 어려운 이유
인덱스가 많으면 생기는 문제점
DML 성능 저하 - TPS 저하
데이터베이스 사이즈 증가 - 디스크 공간 낭비
데이터베이스 관리 및 운영 비용 상승
신규 데이터를 입력할 때, 모든 인덱스에 데이터 입력해야 함
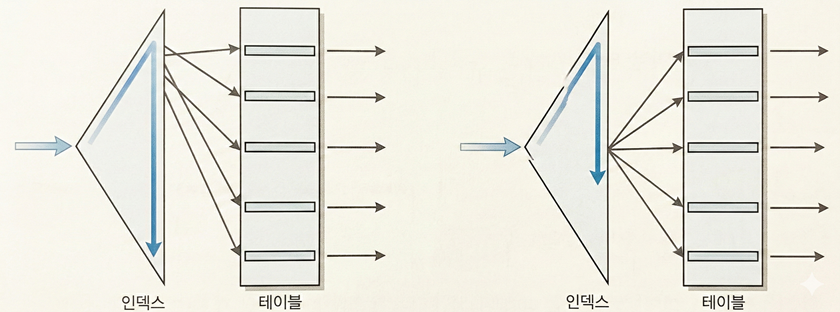
인덱스는 정렬 상태를 유지해야 하므로, 수직적 탐색을 통해 입력할 블록부터 찾음
찾은 블록에 여유 공간이 없으면 인덱스 분할도 발생
데이터를 지울 때에도 모든 인덱스에서 레코드를 찾아 지워야 함
개발 단계에서 최적 인덱스 설계의 중요성
인덱스 개수를 최소화하려면 기존 인덱스 구성을 변경함으로써 문제를 해결
인덱스 변경에 따른 시스템 변경 영향도가 매우 커서 쉽지 않음
영향받는 SQL을 모두 찾아 검증해야 하기에, 운영 환경에서 쉽지 않음
신규 인덱스 추가는 변경 영향도가 적음
그러나 시스템 수준 TPS는 점점 나빠짐
따라서 개발 단게에서 인덱스를 최적으로 설계하는 일이 매우 중요
가장 중요한 두 가지 선택 기준
인덱스 스캔 방식 중 가장 정상적이고 일반적인 방식은 Index Range Scan
인덱스 선두 컬럼을 조건절에 반드시 이용해야 함
첫 번째 기준은 조건절에 항상 사용하거나, 자주 사용하는 컬럼을 선정하는 것
두 번째 기준은 선정한 컬럼 중 = 조건으로 자주 조회하는 컬럼을 앞쪽에 두어야 한다는 것
스캔 효율성 이외의 판단 기준
두 가지 기준은 인덱스 스캔 효율성이 판단 기준
그 외의 고려할 점
수행 빈도
업무상 중요도
클러스터링 팩터
데이터량
DML 부하
기존 인덱스 개수, 초당 DML 발생량, 자주 갱신하는 컬럼 포함 여부 등
저장 공간
인덱스 관리 비용 등
특히 수행 빈도의 경우, 자주 수행하지 않는 SQL이면 인덱스 스캔 과정에 약간의 비효율이 있어도 큰 문제가 아닐 수 잇음
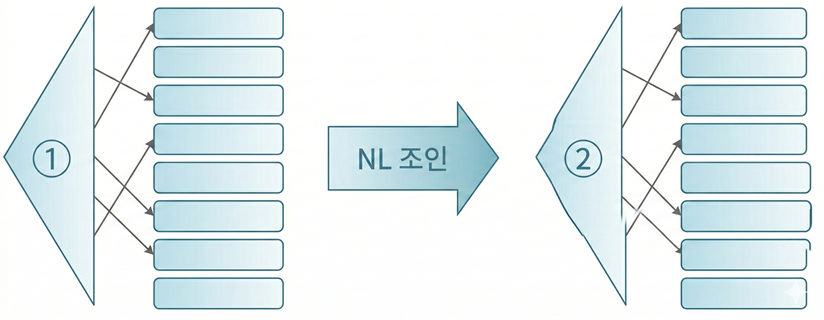
NL 조인할 때, Outer 쪽(드라이빙 집합)에서 엑세스하는 인덱스(1번)는 스캔 과정에 비효율이 있더라도 큰 문제가 아닐 수 있음
반대로 NL 조인에서 Inner 쪽 인덱스(2번) 스캔 과정에 비효율이 있다면, 이는 성능에 큰 문제가 생길 수 있음
select/*+ leading(a) use_nl(b) */
b.상품코드, b.상품명, a.고객번호, a.거래일자, a.거래량, a.거래금액
from 거래 a, 상품 b
where a.거래구분코드 ='AC'and a.거래일자 between'20090101'and'20090131'and b.상품번호 = a.상품번호
and b.상품분류 ='가전'
거래쪽 인덱스가 (거래일자 + 거래구분코드)인 경우
거래 쪽 인덱스를 스캔하는 과정에서 비효율이 있더라도 NL 조인 매커니즘 상 비효율은 한 번
불필요한 테이블 엑세스는 발생하지 않으므로, 넓은 거래일자 구간으로 조회하지 않는다면 괜찮음
성능에 문제가 없다면 굳이 (거래구분코드 + 거래일자) 인덱스 불필요
select/*+ leading(b) use_nl(a) */
b.상품코드, b.상품명, a.고객번호, a.거래일자, a.거래량, a.거래금액
from 거래 a, 상품 b
where a.거래구분코드 ='AC'and a.거래일자 between'20090101'and'20090131'and b.상품번호 = a.상품번호
and b.상품분류 ='가전'
거래쪽 인덱스가 (거래일자 + 상품번호 + 거래구분코드) 순인 경우
BETWEEN 조건 컬럼이 인덱스 선두 컬럼이므로 Outer 테이블로부터 엑세스하는 횟수만큼 비효율적인 스캔 반복
수행빈도가 높은 SQL이라면 테스트 과정에서 성능이 좋게 나오더라도 인덱스를 최적으로 구성해야 함
NL 조인 Inner쪽 인덱스는 '=' 조건 컬럼을 선두에 두는 것이 중요
될 수 있으면 테이블 엑세스 없이 인데스에서 필터링을 마치도록 구성
데이터량도 중요한 기준
데이터량이 적다면 굳이 인덱스를 많이 만들 필요 없이 Full Scan으로 충분히 빠름
인덱스를 많이 만들어도 저장 공간이나 트랜잭션 부하 측면에서 그다지 문제될 것이 없음
초대용량의 경우, DML 발생량이 트랜잭션 성능(TPS)에 직접적인 영향을 줌
공식을 초월한 전략적 설계
최적을 달성해야 할 여러 엑세스 경로 중 가장 핵심적인 경로를 선택해서 최적 인덱스를 설계하고, 나머지는 약간의 비효율이 있더라도 목표 성능을 만족하는 수준으로 인덱스를 구성해야 함
단순 공식이 아닌, 업무 상황을 이해하고 나름의 판단 기준이 필요
예시
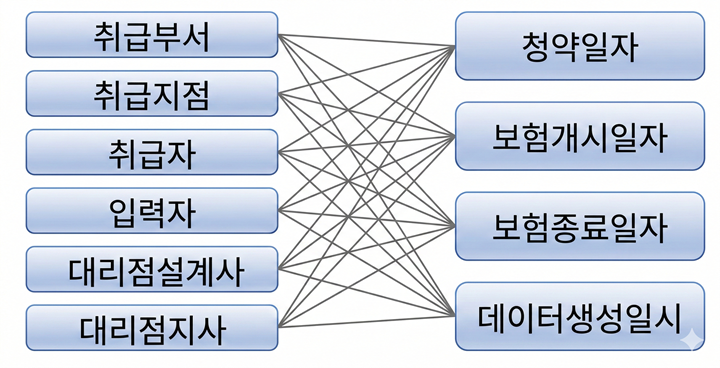
가계약 테이블
가계약 목록을 조회할 때, 취급부서 ~ 대리점지사 중 하나 선택
조건절은 =
그리고 청약일자 ~ 데이터생성일시 중 하나 선택
조건절은 BETWEEN
두 항목에 대한 값을 입력 후 조회
인덱스 스캔 효율을 위해 '=' 조건 컬럼을 앞에, BETWEEN 조건 컬럼을 뒤에 두려면 24개의 인덱스가 필요
사용자가 인내할 수 있는 수준의 인덱스 스캔 비효율이더라도 BETWEEN 조건 컬럼을 선두에 두고 설계하는 것이 마음에 걸림
가계약 테이블을 다양한 패턴으로 조회하지만, 가장 많이 사용하는 패턴은 입력자 '=', 데이터생성일시 BETWEEN
해당 패턴에 최적의 스캔 효율을 제공하면, 다른 패턴에 다소 비효율이 있어도 크게 지장 없음
X05: 입력자 + 데이터생성일시
여러 요소를 고려해, 인덱스 총 5개를 사용
소트 연산을 생략하기 위한 컬럼 추가
인덱스는 항상 정렬 상태를 유지하므로 ORDER BY, GROUP BY를 위한 소트 연산을 생략할 수 있게 해줌
조건절에 사용하지 않더라도, 소트 연산 생략 목적으로 인덱스 구성에 포함시킬 수 있음
select 계약ID, 청약일자, 입력자ID, 계약상태코드, 보험시작일자, 보험종료일자
from 계약
where 취급지점ID = :trt_brch_id
and 청약일자 between :sbcp_dt1 and :sbcp_dt2
and 입력일자 >= trunc(sysdate -3)
and 계약상태코드 in ( :ctr_stat_cd1, :ctr_stat_cd2, :ctr_stat_cd3 )
orderby 청약일자, 입력자ID
성능을 고려하지 않는다면, ORDER BY 순서대로 (청약일자 + 입력자ID) 인덱스 구성
'=' 조건절 컬럼은 ORDER BY 절에 없더라도 인덱스 구성에 포함할 수 잇음
(청약일자 + 취급지점ID + 입력자ID) 로 구성해도 소트 연산 생략 가능
위치는 앞뒤 중간 상관 없음
'='이 아닌 조건절 컬럼은 반드시 ORDER BY 컬럼보다 뒤쪽에 두어야 소트 연산 생략 가능
문제는 조건을 만족하는 데이터를 빨리 만날 수 있느냐
운좋게 앞쪽에서 만나면 결과집합이 빨리 출력되기 시작
맨 뒤쪽에서 만나면 사용자는 그때까지 기다려야 함
DBMS 내부에서는 테이블 필터를 포함해 많은 I/O가 발생
I/O를 최소화하면서 소트 연산도 생략하려면
'=' 연산자로 사용한 조건절 컬럼 선정
ORDER BY 절에 기술한 컬럼 추가
'=' 연산자가 아닌 조건절 컬럼은 데이터 분포를 고려해 추가 여부 결정
즉, (취급지점ID + 청약일자 + 입력자ID)
입력일자와 계약상태코드는 뒤에 붙여도 되고 안 붙여도 됨
조건을 만족하는 데이터가 적으면, 테이블 랜덤 엑세스를 줄이기 위해 붙이면 좋음
IN조건은 '='이 아니다
IN 조건은 '='이 아니기 때문에 계약상태코드를 인덱스 앞쪽에 두어도 소트연산 생략 불가
select 고객번호, 고객명, 거주지역, 혈액형, 연령
from 고객
where 거주지역 ='서울'and 혈액형 in ( 'A', 'O' )
orderby 연령
거주지역
혈액형
연령
서울
A
23
서울
A
35
서울
A
48
서울
A
62
서울
O
29
서울
O
32
서울
O
45
서울
O
57
IN 조건이 '='이 되려면 IN-List Iterator 방식으로 풀려야 함
IN 조건이 '='이 됐지만, UNION ALL 위아래 두 집합을 묶어 '연령'순으로 정렬하는 문제가 남음
select 고객번호, 고객명, 거주지역, 혈액형, 연령
from 고객
where 거주지역 ='서울'and 혈액형 ='A'unionallselect 고객번호, 고객명, 거주지역, 혈액형, 연령
from 고객
where 거주지역 ='서울'and 혈액형 ='O'orderby 연령
ORDER BY 절이 있음에도 소트 연산을 생략하려면, 위쪽 브랜치를 실행하고 이어서 아래쪽을 실행했을 때 그 결과가 연령 순으로 정렬돼야 함
서울에 거주하는 모든 A형 고객이 O형 고객보다 어려야 함
불가능한 일이므로 옵티마이저는 소트 연산을 생략하지 않음
소트 연산을 생략하려면 IN 조건절이 IN-List Iterator 방식으로 풀려선 안 됨
IN 조건절을 인덱스 엑세스 조건이 아닌 필터 조건으로 사용해야 함
(거주지역 + 연령 + 혈액형) 인덱스를 구성해야 함
결합 인덱스 선택도
선택도가 충분히 낮은지는 인덱스 생성 여부 결정의 중요한 기준
선택도(Selectivity): 전체 레코드 중에서 조건절에 의해 선택되는 레코드 비율
선택도에 총 레코드 수를 곱하면 카디널리티
인덱스 선택도는 인덱스 컬럼을 모두 '='로 조회할 때 평균적으로 선택되는 비율
선택도가 높은 인덱스는 테이블 액세스가 많이 발생해 별 효용이 없음
인덱스를 생성할 때 반드시 선택도/카디널리티를 확인
selectcount(*) as NDV, max(cnt) as MX_CARD, min(cnt) MN_CARD, avg(cnt) as AVG_CARD
from (
select 계약ID, 취급지점ID, count(*) as cnt
from 계약조직
where (계약ID isnot nullor 취급지점ID isnot null)
groupby 계약ID, 취급지점ID
)
컬럼 순서 결정 시, 선택도 이슈
결합 인덱스 컬럼 간 순서를 정할 때 선택도가 중요하지 않음
선택도가 낮은 컬럼을 앞에 두는 게 유리하다는 것은 잘못된 지식
-- 둘 다 인덱스 엑세스 조건이므로 어떤 컬럼이 앞으로 오든 인덱스 스캔 범위는 같음WHERE 성별 = :GENDER
AND 고객번호 = :CUST_NO
인덱스 설계시, 항상 사용하는 컬럼을 앞쪽에 두고 그 중 '=' 조건을 앞쪽에 위치시키는 것
선택도가 낮은 컬럼을 앞에 두는 것은 의미가 없거나 손해일 수 있음
-- 조건1WHERE 고객등급 = :V1
AND 고객번호 = :V2
AND 거래일자 >= :V3
-- 조건2WHERE 고객등급 = :V1
AND 고객번호 = :V2
AND 거래일자 >= :V3
AND 거래유형 = :V4
-- 조건3WHERE 고객등급 = :V1
AND 고객번호 = :V2
AND 거래일자 >= :V3
AND 상품번호 = :V5
-- 조건4WHERE 고객등급 = :V1
AND 고객번호 = :V2
AND 거래일자 >= :V3
AND 거래유형 = :V4
AND 상품번호 = :V5
항상 사용하는 고객번호, 고객등급, 거래일자 중 고객번호와 고객등급은 '=' 조건, 거래일자는 BETWEEN
고객등급과 고객번호 중 어떤 컬럼이 앞으로 오든 인덱스 스캔 효율에 영향이 없음
거래일자까지 세 컬럼이 엑세스 조건이므로 인덱스 스캔 범위는 같음
거래유형과 상품번호 간에 어떤 컬럼이 앞으로 오든 인덱스 스캔 효율에 영향이 없음
인덱스 스캔 범위가 앞 세 컬럼에 의해 결정되므로
고객등급, 고객번호 둘 다 필수 '=' 조건이라면 어떤 컬럼이 앞으로 오든 상관 없지만, 하나 이상이 조건절에서 누락되거나 범위검색 조건일 수 있다면 복잡해짐
고객번호 필수 & 고객등급이 조건절에서 누락되거나 범위검색 조긴일 수 있는 경우
고객등급을 앞에 두는 것이 유리
Index Skip Scan이나 IN-List 조건 활용이 가능해서
인덱스를 압축할 경우, 고객등급을 앞쪽에 두면 압축률이 더 좋은 측면
인덱스 생성 여부를 결정할 때 선택도가 매우 중요하지만, 컬럼 간 순서를 결정할 때는 필수 조건 여부, 연산자 형태가 더 중요함
중복 인덱스 제거
예시1
인덱스
X01 : 계약ID + 청약일자
X02 : 계약ID + 청약일자 + 보험개시일자
X03 : 계약ID + 청약일자 + 보험개시일자 + 보험종료일자
X02 인덱스 선두 컬럼이 X01 인덱스를 완전 포함하고, X03 인덱스 선두 컬럼이 X01, X02 인덱스 전체를 완전 포함
X03을 제외한 인덱스를 삭제해도 됨
예시2
인덱스
X01 : 계약ID + 청약일자
X02 : 계약ID + 보험개시일자
X03 : 계약ID + 보험종료일자
X04 : 계약ID + 데이터생성일시
두 번째 컬럼이 모두 달라 중복이 아닌 것처럼 보이지만, 계약ID의 평균 카디널리티가 매우 낮다면 사실상 중복
계약ID 평균 카디널리티가 5라면, 계약ID를 '='조건 조회시 평균 다섯 건이 조회
인덱스를 4개씩 만들 필요가 없음
다음 인덱스 하나로 충분
X01 : 계약ID + 청약일자 + 보험개시일자 + 보험종료일자 + 데이터생성일시
실습1
인덱스
PK : 거래일자 + 관리지점번호 + 일련번호
N1 : 계좌번호 + 거래일자
N2 : 결제일자 + 관리지점번호
N3 : 거래일자 + 종목코드
N4 : 거래일자 + 계좌번호
거래일자, 결제일자는 항상 BETWEEN 조회
컬럼명
NDV
거래일자
2,356
관리지점번호
127
일련번호
1,850
계좌번호
5,956
종목코드
1,715
결제일자
2,356
거래일자가 항상 BETWEEN 조건이면 N3, N4 인덱스는 둘 다 거래일자가 인덱스 엑세스 조건
인덱스를 두 개나 만들 필요 없음
N4를 제거하고, N3를 (거래일자 + 종목코드 + 계좌번호)로 변경
또는 N3 변경 없이 N4 제거
계좌번호와 거래일자로 조회할 때는 N1 인덱스를, 거래일자만으로 조회할 때는 N3 인덱스 사용
조건절
인덱스
계좌번호 =
N1
계좌번호 =, 거래일자 =
N1
계좌번호 =, 거래일자 BETWEEN
N1
거래일자 =
N3
거래일자 BETWEEN
N3
최종 제안
PK : 관리지점번호 + 거래일자 + 일련번호
N1 : 계좌번호 + 거래일자
N2 : 결제일자 + 관리지점번호
N3 : 거래일자 + 종목코드
관리지점번호가 선두 컬럼인 인덱스가 없었으므로 관리지점번호 단독으로 조회하는 경우는 없었던 것으로 추정
PK를 그대로 두면 관리지점번호 '=', 거래일자 BETWEEN으로 조회할 때 비효율적
관리지점번호와 거래일자로 조회할 때는 PK 인덱스를, 거래일자만으로 조회할 때는 N3 인덱스 사용
조건절
인덱스
관리지점번호 =, 거래일자 =
PK
관리지점번호 =, 거래일자 BETWEEN
PK
거래일자 =
N3
거래일자 BETWEEN
N3
실습2
인덱스
PK : 주소ID + 건물동번호 + 건물호번호 + 관리번호
N1 : 상태구분코드 + 관리번호
N2 : 관리번호
N3 : 주소ID + 관리번호
컬럼명
NDV
주소ID
736,000
건물동번호
175
건물호번호
3,052
관리번호
250,782
상태구분코드
3
상태구분코드 NDV는 3이므로 선택도가 매우 높음
상태구분코드로만 조회할 때는 N1 인덱스가 사용되지 않음
상태구분코드와 관리번호를 같이 조회해야 N1이 사용됨
N2는 관리번호를 조회할 때만 사용되므로 N2를 제거하고, N1을 (관리번호 + 상태구분코드)로 변경
관리번호로만 조회하든, 상태구분코드까지 같이 조회하든 N1 사용
상태구분코드 NDV가 3이긴 하나, 특정 값은 변별력이 매우 좋을 수 있ㅇ므
그 값으로 조회할 때 사용할 목적으로 N1을 만들었다면, N1 변경 시 문제가 생길 수 있음